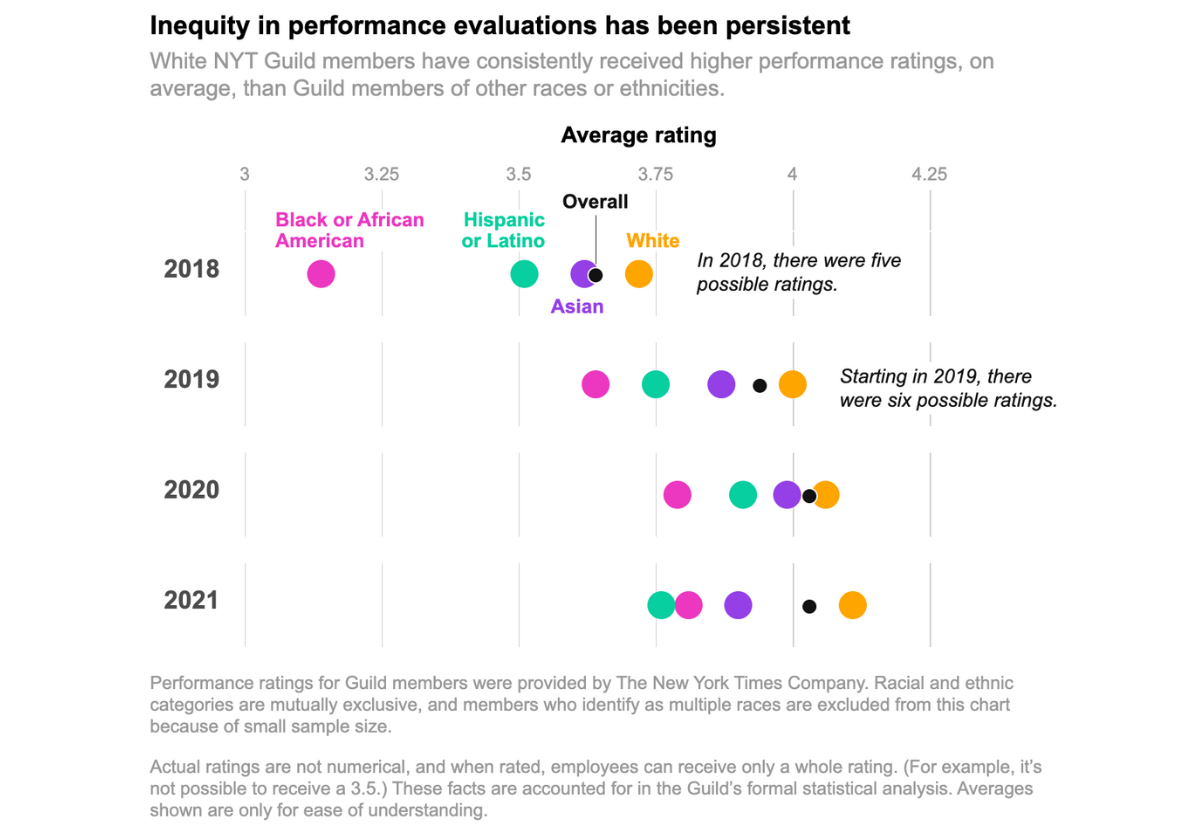
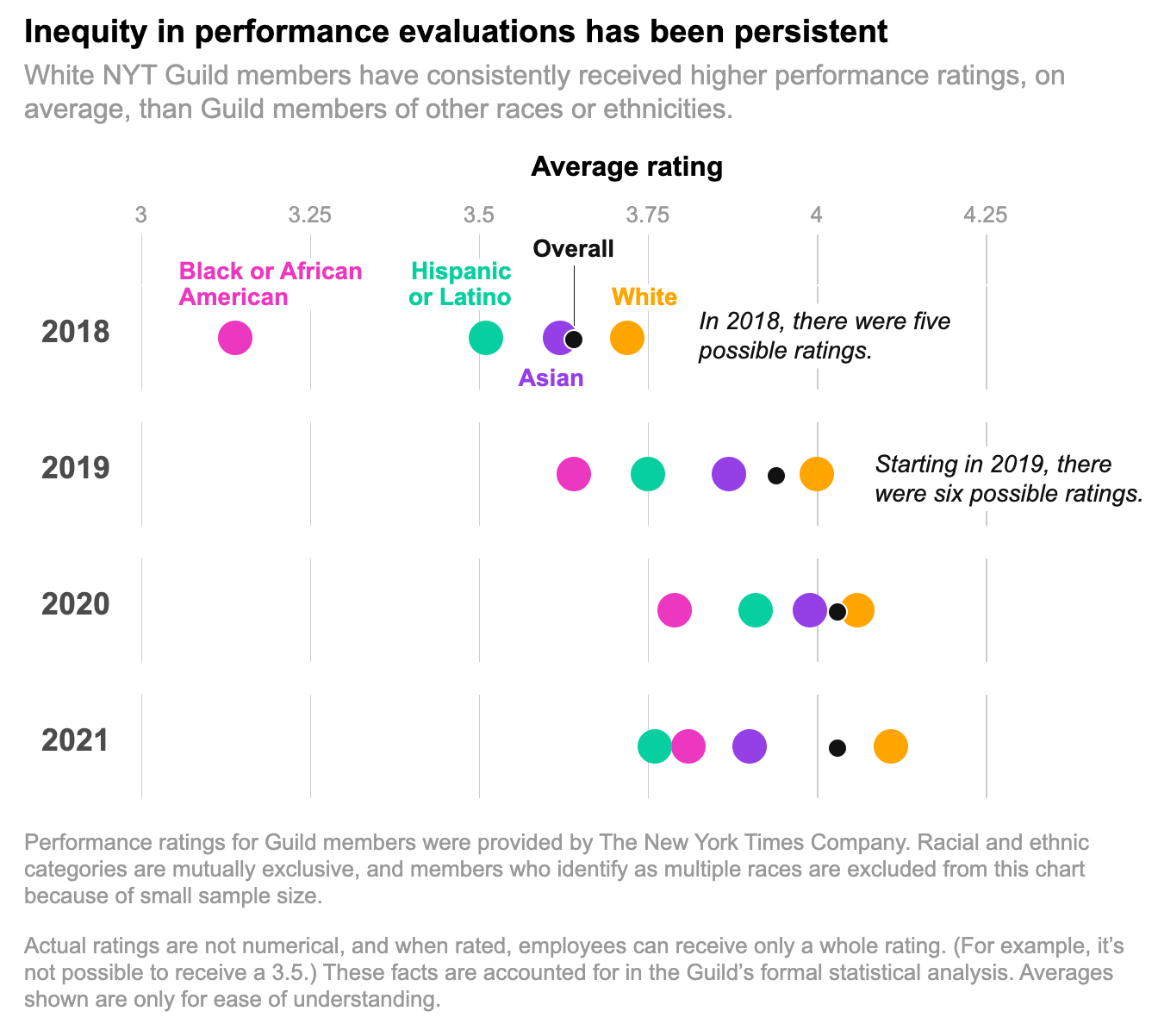
The New York Times’s performance review system has for years given significantly lower ratings to employees of color, an analysis by Times journalists in the NewsGuild shows.
The analysis, which relied on data provided by the company on performance ratings for all Guild-represented employees, found that in 2021, being Hispanic reduced the odds of receiving a high score by about 60 percent, and being Black cut the chances of high scores by nearly 50 percent. Asians were also less likely than white employees to get high scores.
In 2020, zero Black employees received the highest rating, while white employees accounted for more than 90 percent of the roughly 50 people who received the top score.
The disparities have been statistically significant in every year for which the company provided data, according to the journalists’ study, which was reviewed by several leading academic economists and statisticians, as well as performance evaluation experts.
Performance ratings have a direct impact on employees’ paychecks and career opportunities. In 2021, the company used the scores in determining the size of Guild members’ bonuses. Guild members who believed their contributions weren’t fairly rated in the review process have said they feel demoralized and alienated — a pernicious outcome as The Times attempts to recruit and retain a diverse workforce. Management has denied the discrepancies in the performance ratings for nearly two years, time it could have instead spent trying to make the system better for everyone.
The performance rating system has changed over time, and the precise nature of the racial disparities has varied somewhat from year to year. But what has remained consistent is that white Guild members, on average, receive higher ratings than their colleagues of color. These findings showed up under a variety of different methodological approaches, including those suggested by the company itself.
A History of Questionable Denials
For nearly two years, company management has downplayed the extent of the problem, which journalists with the Guild first pointed out in a 2020 report using data from 2018 and 2019. Responding a few months later, executives acknowledged that Black employees were underrepresented at the top scores company-wide, but said that there were no problematic discrepancies when the scores were evaluated separately for each department.
The executives also said the company disagreed with the Guild members’ analysis, but — in a move familiar to journalists — management did not respond to requests to identify errors.
The latest Guild study comes after members requested that the company provide updated data. The company is required to respond to such union requests, but does not supply information for non-union employees.
After conducting a new analysis, the journalists raised the issue as part of the contract negotiation process. In response, the company hired an outside consultant to analyze the ratings data. It concluded that disparities were minimal and inconsistent, and that therefore there was no evidence of a systemic problem. The company disclosed more information about its analysis but has not responded to the Guild request to provide a copy.
Multiple outside experts consulted by the reporters consistently said the methodology used in the Guild’s most recent analysis was reasonable and appropriate and that the approach used by the company appeared either flawed or incomplete. Some went further, suggesting the company’s approach seemed tailor-made to avoid detecting any evidence of bias.
Rachael Meager, an economist at the London School of Economics, was blunt: “LMAO, that’s so dumb,” she wrote when Guild journalists described the company’s methodology to her. “That’s what you would do if you want to obliterate signal,” she added, using a word that in economics refers to meaningful information.
“This is so stupid as to border on negligence,” added Dr. Meager, who has published papers on evaluating statistical evidence in leading economics journals.
Peter Hull, a Brown University economist who has studied statistical techniques for detecting racial bias, also questioned the company’s approach and recommended a way to test it: running simulations in which bias was intentionally added. The company’s method repeatedly failed to detect racial disparities in those tests.
Richard Tonowski, the former chief psychologist for the Equal Employment Opportunity Commission and a specialist in the analysis of performance appraisals, said the journalists’ analysis was sound. After journalists informed him that the company was citing E.E.O.C. guidelines as justification for using its methodology, he said it was incorrect to interpret the guidelines as directing companies to use this approach.
Dr. Tonowski added that the company could improve its analysis by using multiple statistical techniques and looking at the data over several years. With three years of data, even the company’s preferred approach finds statistically significant disparities at many ratings levels.[1]
The company relied in part on analysis by outside consulting and law firm Seyfarth Shaw, which gained attention decades ago for representing California growers against workers led by Cesar Chavez and more recently for representing the Weinstein Company in harassment suits.
The Guild shared its findings, in detail, with Times management prior to the publication of this report. In a response on Friday, Aug. 19, company representatives said they were committed to “a performance evaluation system that is fair and equitable,” but criticized the Guild for not giving them more time to review these findings. The Guild believes the company has had ample opportunity over nearly two years to address these disparities, and has instead chosen to downplay them. (For the company’s full comment, and a more complete response from the Guild, see the section at the end of this report.)
Real Effects on Employees
Management’s delays in acknowledging and addressing problems in the system have a real effect on Guild colleagues. In interviews, employees described the performance review process as confusing and frustrating. Some said they had received glowing written and verbal reviews that were then followed by surprisingly low ratings.
“Although my work consistently performed well with readers and earned high-level praise, my scores did not reflect this,” said one employee of color, who spoke on condition of anonymity because of fears of job repercussions. “By the time I received my first positive performance review, I’d already concluded that the reviews were unrelated to the quality of my work. I do my best not to pay attention to them,” the person said.
Another journalist of color said they left The Times because they received negative performance review scores without clear guidance on expectations or ways to improve — and despite being lauded externally.
Recently, the company has started using the results to help determine yearly bonuses. Most workers who received the top rating got a 1.9 percent bonus, while those who received a rating of “meets expectations” got 1.5 percent. Employees who got the two lowest ratings received no bonus at all.
The Guild agrees that documented reviews are better than an opaque system for allocating bonuses, but members have regularly said the process is bewildering and is a particularly bad fit for people in creative newsroom positions. Some suggested that low scores felt needlessly demoralizing for journalists who are clearly at the top of their field.
Several members recalled conversations in which their manager told them that top scores were only for people who were being promoted, that new employees could not receive the highest scores, or that the company forced reviewers to lower scores in a given department if too many high scores had been assigned.
Company executives have repeatedly denied that this is the case and have said that managers are free to give everyone in the department the highest scores possible if they are performing well. “There’s no quota system,” Cliff Levy, a deputy managing editor, said at a May 2021 bargaining session.
In the same session, Elise Baron, the company’s executive director and head of H.R. business partners, said: “We have never told any managers ‘you can only give so many of a rating.’ … We ask questions, like ‘Does this really fit the description of the rating? Can you give me examples?’ But we never, ever come back and say ‘You need to change this, the rating is too high.’”
Management’s Proposal: Ignore the Problem and Expand a Flawed System
In contract negotiations, company management has sought unilateral control over the performance review system and the right to make significant changes to it without bargaining them with the Guild. The company is also seeking the right to conduct mandatory reviews as often as it wants. Issuing ratings twice a year, not just once, is actively under consideration, company negotiators have said.
The Guild opposes such an expansion.
The Times has agreed to create a committee of three Guild members and three management representatives to discuss ways to improve the performance review process. This is a good step, but the Guild believes discussions will be fruitless if the company continues to ignore the disparities revealed in the review process. The Guild is seeking a commitment to analyze the system using multiple methods, rather than the company’s flawed approach.
The company has also agreed to allow employees to see drafts of their written reviews and to provide workers with an opportunity to contest them before they are finalized. Again, this is an improvement, but the Guild is also seeking to make sure the employee can also see their rating and discuss – or, where necessary, contest – it before submission. (Currently, managers submit scores to desk heads and H.R. even before drafting written reviews, and before having a discussion with the employee.)
Both sides have expressed interest in creating a formal appeals process.
It is not clear whether the racial imbalance is a result of problems in the performance review system itself or whether that system is simply revealing barriers to success for employees of color at the company. The Guild’s position is that an open process for evaluating employees is preferable to one that is wholly opaque, but that there must be changes — both to the review system and to any areas of the company where the analysis shows greater disparities.
For example, the analysis by the Guild journalists indicates that racial disparities are larger among newer employees than among those who have been with the company longer (although the disparities are present for all groups). Management’s response to this finding has been to say that racial imbalance decreases when they “correct for tenure.” A more productive response would be to acknowledge that the performance review data reveals evidence of a problem and to focus attention on improving the experience of newly hired employees of color.
Thus far, management representatives have refused to discuss such options.
For a deeper explanation of the analysis, read on.
The Guild’s findings and analysis
For the past three years, the company has reviewed Guild employees on a six-tier scale:
- “Doesn’t meet expectations”
- “Partially meets expectations”
- “Meets all expectations”
- “Exceeds various expectations”
- “Frequently exceeds expectations”
- “Substantially surpasses expectations”
In practice, hardly anyone gets the lowest rating of “doesn’t meet expectations.” Only three people have gotten that rating over the past three years, and none in 2021.
That means there is, in effect, a five-tier system, with “exceeds various expectations” in the middle. In all three years, a bit more than 40 percent of Guild members received this middle rating. About 25 percent of members received each of the ratings just above or just below that midpoint. The remaining roughly 10 percent of members were divided between the top (“substantially surpasses expectations”) and bottom (“partially meets expectations”) ratings.
Those distributions look significantly different for different races, however. Specifically, white Guild members were more likely to get the top ratings, while Black and Hispanic members were more likely to get the lowest two ratings. In 2021, 32 percent of white Guild members received a rating in one of the top two categories, compared with 21 percent of Hispanic members and 18 percent of Black members. But only 25 percent of white members received one of the lowest two ratings, compared with 49 percent of Hispanic or Latino members and 36 percent of Black members.
Put another way: Black employees made up 10 percent of the Guild’s total membership in 2021, but received nearly 18 percent of the sub-par “partially meets expectations” ratings given out that year, and just 6 percent of the top “substantially surpasses expectations” ratings.
There are similar disparities in earlier years.

Those disparities are alarming. But, in theory, it is possible that they could be due to random chance, or could be explained by factors other than racial bias. In order to explore those possibilities, we need to run a more sophisticated analysis known as a regression model.
Regression models are statistical models that allow us to test whether and how much one variable affects the outcome of another variable. This kind of analysis can show, for example, whether people with more years of schooling tend to earn more money, and can quantify how much someone would be expected to earn if they stayed in school for one additional year. Regression analyses also allow us to control for other variables that might play a role; it might make sense, for example, to factor in how much money a child’s parents earn, to account for the possibility that children with rich parents tend to stay in school longer. Lastly, regression models allow us to quantify uncertainty, so we can estimate how likely it is that our findings are due to random chance.
For our analysis of performance reviews, the experts consulted by the Guild recommended a type of regression model known as an “ordered logistic regression” or “ordered logit.[2]” This type of model accounts for the fact that performance reviews are ranked but not strictly numeric, much like letter grades. In other words, the rating “exceeds various expectations” is better than “partially meets expectations,” but it isn’t necessarily twice as good.
In the simplest form of our analysis, we used this type of regression to evaluate the relationship between performance reviews and race or ethnicity, controlling for department.
Performance reviews are conducted at the department level, so there is an argument to be made that they should also be analyzed only at that level, because departments might approach performance reviews differently. But breaking analysis down by department can hide disparities, because many departments are small, and there might not be enough people in them to achieve statistical significance. Or departments with more employees of color could rate all their employees more harshly, meaning that the department itself wouldn’t show evidence of bias, but there might be an unfair situation for employees of color at the company nonetheless. We made sure our analysis accounted for all of these issues.
This analysis finds that in 2021, being Black reduced the odds of receiving a high rating by about 50 percent relative to white Guild members, being Hispanic or Latino reduced the odds by about 60 percent, and being Asian reduced the odds by about 35 percent.[3] For all three groups, those disparities were statistically significant at the 95 percent confidence interval.[4] This is a standard measure of statistical significance and means that we are 95 percent confident that belonging to one of these groups had a negative effect on the chances of being rated highly in 2021.
| If you are … | You were … |
|---|---|
| Black | 47.2 percent less likely than a white employee to receive a high rating in 2021 |
| Hispanic | 61.2 percent less likely |
| Asian | 34.2 percent less likely |
We found statistically significant disparities affecting Black employees in every year for which data was available, and affecting Hispanic and Asian employees in some years.
We also ran our analysis with controls for age, gender and length of service with The Times. That approach made hardly any difference for Black employees in 2021, and actually showed wider disparities for Hispanic and Asian employees. All the disparities were, once again, statistically significant. (It is worth noting that we found no evidence of bias by gender.)
Nearly every expert we spoke to recommended using an ordered logistic regression. But several also suggested other possible approaches. We also ran our analysis using a Poisson regression, a linear regression and a variety of hierarchical mixed-effects models, and we performed a Kruskal-Wallis test. We also performed an ordinal Cochran-Mantel-Haenszel test, a variation of the method used by the company, which we will describe in more detail in the next section. Each of these approaches found statistically significant racial disparities.
From the start of this project two years ago, the Guild’s goal has been to understand the performance review system and to see whether there were disparities that needed addressing. We did not set out with a thesis in mind, or with the goal of making the company look bad. When our preliminary analysis suggested a possible problem, we dug deeper, trying different approaches to make sure that our findings were not a fluke, consulting experts to make sure that our methodology was sound, and adjusting our analysis in response to management’s concerns. What we found, over and over again, was that no matter what method we chose, or how we tweaked our analysis, the results were the same: Our Black and Hispanic colleagues receive statistically lower ratings than their white counterparts.
Management’s flawed analysis
At the bargaining table, management has repeatedly denied that analysis of the performance review system reveals systemic racial discrepancies. In a recent all-company meeting, Lauren Lopez, senior vice president for talent management, defended the system but acknowledged finding some disparities. She said:
“We saw overrepresentation at ‘meets all expectations’ rating for Black and Hispanic employees and underrepresentation at some of the higher ratings. We dug deeper to try to understand the reasons for these trends and learned that management level and tenure play a significant role in these results. Taking these factors into account eliminated or largely reduced the differences. So, in other words, under-representation in leadership and shorter tenure for Black and Hispanic colleagues largely explain the trends we are seeing, and it may take time to eliminate those differences entirely.”
Even taking these comments at face value, these findings should be cause for concern. Black and Hispanic employees, by the company’s own admission, are more likely to get the sub-par “meets all expectations” rating, and less likely to get higher ratings. The company says these disparities are “eliminated or largely reduced” after taking into account management level and tenure, but even if that is true, it does not mean there is no problem: Employees of every experience and management level ought to have the same opportunity to get a high rating (and the larger percentage bonus that comes with it).
Instead, this creates an extra burden for newer employees. The Guild does not have access to data on excluded (non-Guild-represented) Times employees, so we could not look at management level. But we did factor length of service into our analysis. We found that including length of service did not eliminate the disparities, but that it is true that the disparities are greatest for the newest employees. We would argue, however, that this is not a mitigating factor, but rather evidence of a serious problem at a time when The Times is trying to diversify its staff.
If our recently hired Black and brown colleagues are disproportionately receiving low performance ratings, that suggests that The Times is not doing an effective job making our workplace a welcoming and nurturing environment for all employees – something we have heard anecdotally from many current and former colleagues, some of whom left the company for this exact reason.
Leaving such issues aside, however, why does the company’s analysis not show the same large and persistent disparities as the Guild’s? We asked management to describe its methodology so we could understand the disconnect. They eventually explained that their analysis was based on a “binomial test” for each race and ratings score, for each department. They then aggregated the department results using a technique called a Mantel-Haenszel test.
In plain English, what this means is that the company performed a separate analysis for every rating level and every race at every department. In other words, they looked at whether Black employees on the Business desk were statistically less likely than white colleagues on that desk to get a “partially meets expectations” rating. Then they did the same for the same group of employees looking at the “meets all expectations” rating. And so on for each rating, and each under-represented racial or ethnic group, in each department[5]. In each case, they examined whether there was a statistically significant disparity.
The company also aggregated these department-level results in order to see whether there were disparities at the company-wide level. In theory, this is a reasonable approach.
But there was one major flaw in the company’s method: It conducted a separate analysis for each performance rating.
By looking at each rating separately, the company is breaking down its analysis into smaller groups, and smaller groups are naturally less likely to display statistical significance.
For each category, the company used a binomial test. This is what statisticians use when they are dealing with separate, unrelated categories or yes/no questions. For example, they might use it to determine whether Black employees are more or less likely than white employees to be hired to the Business desk, or whether Hispanic employees are more likely to work in the Washington bureau. But it is a wholly inappropriate approach when dealing with an ordinal variable like performance ratings, where the results are clearly related and one rating is better than another.
In fact, the company’s method frequently failed to find statistically significant racial disparity even on a series of dummy datasets in which we intentionally inserted significant bias.[6] In our experiment, we randomly assigned white employees to performance ratings in each department, with the exact probabilities we see in the real data. (In other words, if 35 percent of employees in advertising get a rating of “meets all expectations,” then white advertising “employees” in our simulation had a 35 percent chance of getting that rating.) We did the same for our simulated “Black employees,” except we penalized them: In the first set of simulations, they had a 20 percent lower chance of getting the top two ratings, and a 20 percent higher chance of getting the bottom two. Then we applied the company’s methodology to our simulated data to see what it found. We performed the test again with 30 percent bias, then 40 percent. In each case, we ran the simulation 500 times.
In each test, what we found was that the company’s approach frequently failed to detect[7] even severe degrees of bias.[8] In one particularly egregious case, Black employees were 20 times as likely to get the bottom rating, and yet the company’s methodology failed to find statistically significant bias.[9]
Management said it chose its methodology because it considers performance reviews a “selection process,” and selection processes are typically evaluated using a binomial test. To bolster its claims, the company cited documentation on selection processes from the federal government, including the E.E.O.C., the federal agency that investigates employment discrimination.
But Dr. Tonowski, the longtime employee of the E.E.O.C. who assisted the Times reporters in understanding the guidelines, said it was incorrect to interpret them as directing companies to use separate binomial tests to evaluate ordered scores in performance reviews.
In fact, he said, the commission’s guidance on statistical analysis for selection processes is minimal and not directed at performance ratings. Rather, it is focused on ultimate results such as hiring or promotion decisions — the sort of choice that could be evaluated using a binomial test.
Indeed, the very texts cited by the company make this clear. They discuss using such methods not to evaluate raw scores on things like tests or reviews but to detect disparities “caused by use of” them in an actual hiring decision. Selection procedures, the documents say, can include anything from interviews to medical examinations and aptitude tests — items that no statistician would evaluate using the company’s method on each separate score. The guidelines, instead, discuss evaluating whether there is adverse impact on “the final employment decision such as hiring or promoting.”
Dr. Tonowski emphasized that the government guidelines do not preclude companies from using regressions or other types of analysis. The E.E.O.C.’s guidelines were promulgated in 1978 and never revised, he said. This time period was not only before the widespread use of personal computers that could run sophisticated statistical software, but also before the development of the ordered logistic regression model itself.
Dr. Tonowski and other experts told us that companies should use multiple appropriate methods and evaluate data over years to see whether there is evidence of disparity and how the system could be improved.
Looking at the company’s performance review data over the past three years, it becomes clear that employees of color are less likely to receive the highest scores than their white colleagues, and more likely to receive the lowest scores. Indeed, when we apply the company’s approach over three years, rather than just one, it shows that Black Guild members encounter statistically significant disparities at virtually every performance level.
Management’s response to this report
After months of detailed discussions, the Guild shared, in depth, the facts in this report with Times management on Wednesday, Aug. 17, and requested a response no later than Friday, Aug. 19. On Friday, the company responded with the following statement:
“I know we both share the same goal: a performance evaluation system that is fair and equitable and works to develop and support the growth of our colleagues.
“While we appreciate the Guild’s engagement with what we shared, we’re surprised that after the lengthy discussions we’ve had, you gave us such a short time to respond to the summary of your recent analysis. Needless to say, it will take more than 48 hours to fully review what you shared and we would need to see the underlying study.
“We’ve been discussing the PE system for years at the bargaining table. As you know, even though we’ve not agreed with the findings of your previous studies, we have actively engaged with you and the company has dedicated time and resources to continuing to evolve and improve the process. The company hired Lauren Lopez and a team to support her in this important work.”
The Guild appreciates management’s expressions of commitment to a fair and equitable performance evaluation system. But we reject the suggestion that we have not given management sufficient time or information to review our findings.
The Guild first raised concerns about racial disparities in performance reviews nearly two years ago; we shared the basic findings contained in this report four months ago, and described our final methodology to management in early June. And the Guild has repeatedly asked management to review the data on its own in a more robust way. In a meeting with Times representatives in June, Ben Casselman, a Times economics reporter who helped perform the Guild’s analysis, said the following[10]:
“I want to emphasize that I’m not setting out to find something here. I don’t think any of us were. I’ve tried running this a lot of different ways and I keep coming up [with the same] concern. I’m begging you here: I’ll try to replicate your methodology, but we’re hitting this every way we come at it, it’s the same damn thing. It’s deeply troubling to me, and I hope it’s deeply troubling to you.”
During the June meeting, the Guild offered to share its full methodology, including the code used to perform the analysis, with management’s experts, if The Times would agree to do the same. Times representatives declined to do so, and said the Guild could replicate their methodology if we wanted. We did so. The Times had enough information to do the same, if it so chose.
At any time in the last two years, Times management could have performed its own good-faith analysis and reached the same conclusions laid out in this report. Instead, they have chosen to rely on a methodology that our analysis suggests is almost certain to obscure any problems, and then, when presented with a deadline, to complain they were given too little time to respond.
The following is a timeline of our performance review analysis, and our interactions with management:
Nov. 6, 2020: The Guild publishes its first report on disparities in performance review data, using data from 2018 and 2019.
March 2021: Times executives, speaking to staff, acknowledge that Black employees were underrepresented at the top scores company-wide, but they add that there were no problematic discrepancies when the scores were evaluated separately for each department. They state that they take diversity, equity and inclusion seriously, but they disagree with the Guild’s analysis.
March 2021: Times management, in the contract bargaining process, proposes expanding the performance review system.
Early and Mid-2021: The Guild repeatedly requests information on what specific disagreements management has with its analysis and methodology. Management does not provide an answer.
February 2022: The Guild receives information on performance reviews from 2020 and conducts analysis on that data.
April 21, 2022: Guild member Jennifer Valentino-DeVries shares extensive preliminary findings on the 2020 data with management in a bargaining session. Management says it needs time to respond and requests a written report on the methodology and findings.
May 2, 2022: Guild journalists receive from the company more complete performance review data for 2018 through 2021, including more details on department and employee tenure.
May 12, 2022: The Guild provides management with a draft written report of its methodology and findings, after including the new 2021 data. At a bargaining session the same day, Valentino-DeVries presents these findings, and Guild representatives ask management to respond. Management representatives say they do not have experts on hand to discuss the issue; the Guild asks that management bring the appropriate people to the next bargaining session.
May 26, 2022: In a bargaining session, management representatives criticize the Guild’s use of linear regression and say that management’s analysis, using a “binomial test” on each separate rating, finds largely insignificant disparities. Guild members question management’s approach and explain that they used methods in addition to linear regression, all of which showed disparities.
Nevertheless, members promise to consult with experts about the matter, a suggestion that management representatives say is not necessary. Guild representatives ask management to likewise consider other methodological approaches to make sure they are detecting any possible disparities.
Despite promising to bring relevant experts to this session, management representatives at the meeting say they did not perform the analysis and thus cannot answer detailed questions about it. Guild members ask to meet with experts who can.
Late May/early June 2022: Guild journalists contact experts who suggest using an ordered logistic model. Updated analyses using this approach still show large and persistent disparities.
June 8, 2022: Guild representatives meet with Times representatives, including a Seyfarth Shaw economist, who shares details of The Times’s methodology. Management reiterates that it finds no meaningful difference in performance review scores by race or ethnicity.
Guild members provide information on their updated, ordered logit methodology and offer to share their full programming code with the company. This offer is rejected.
June 2022: Guild journalists contact additional experts to inquire about the “binomial test” method, whether it is appropriate for this analysis, and whether its use in evaluating performance reviews is recommended by the federal government. They review E.E.O.C. guidelines, conduct experiments using artificially biased data, and run multiple types of analysis.
Late July/early August 2022: Guild journalists meet with senior members of newsroom leadership to share concerns and to describe findings in more detail.
Aug. 17, 2022: Guild sends detailed “no surprises” letter to Times management outlining its full findings and methodology and asks for a response by Aug. 19.
Aug. 19, 2022: Times management responds to the “no surprises” letter, saying they were “surprised” to have “such a short time to respond” to the Guild’s findings.
This report was produced by the NYT Guild Equity Committee. Its members include:
- Davey Alba
- Bill Baker
- Larry Buchanan
- Quoctrung Bui
- Alex Carp
- Ben Casselman
- Nick Confessore
- Stacy Cowley
- Susan DeCarava
- Michael H. Keller
- Ella Koeze
- Dan Lenos
- Denise Lu
- Jim Luttrell
- Emma Odette
- Shira Ovide
- Frenchie Robles
- Jennifer Valentino-DeVries
Notes:
[1] Dr. Meager, Dr. Hull, Dr. Tonowski and the other experts consulted by the Guild provided advice on methodology, but they did not review the raw performance review data themselves. They spoke in their personal capacity and not on behalf of any current or former employers.
[2] Our earliest analyses used linear regression instead of ordered logistic regression. The outcomes of the two techniques differ slightly but are similar in scope and findings of statistical significance.
[3] These are odds ratios. The coefficients were: -0.638 for Black employees, -0.947 for Hispanic, and -0.419 for Asian. After controlling for differences in department-level ratings, Black employees had a 19.7 percent probability of getting one of the top two ratings in 2021, and a 39.5 percent probability of receiving one of the bottom ratings. White employees, based on the same model, had a 32.3 percent probability of receiving one of the top ratings, and a 24.7 percent probability of receiving one of the bottom ones.
[4] We clustered our standard errors at the department level, and used p < .05 as our standard for statistical significance. For Black members, the 95 percent confidence interval was 40.3 percent to 53.2 percent; for Hispanic members it was 51.1 percent to 69.2 percent; and for Asian members it was 20.5 percent to 45.6 percent.
[5] Management has said it views the department-level analysis as most important, although it also aggregates the results company-wide. The department level typically provides too small of a sample size to detect statistically significant disparities. We believe focusing on departments is the right approach if one wishes to detect individual biased managers, but that is not the issue here.
[6] This approach was suggested to us by Dr. Hull, the Brown University economist and econometrician who has studied statistical methods for detecting racial bias.
[7] When we penalized simulated Black employees by 20 percent, the company’s methodology failed to find statistically significant bias in 92 percent of cases. (Each “case” is a test of a specific performance rating, so there are five tests for each simulation). At a 30 percent penalty, their methodology failed to detect bias 85 percent of the time, and at a 40 percent penalty, it failed to detect bias 75 percent of the time.
[8] In most cases, we have attempted to avoid the word “bias” in this report, because it can imply intention. But in this case, there really is bias – we created it ourselves!
[9] We performed a similar test of our own methodology, to make sure it wasn’t prone to detecting bias that wasn’t there. In this case, we created simulated data in which there was no bias (Black and white employees were randomly assigned to performance ratings at the same rates), and then performed an ordered logistic regression on the simulated data. In 500 simulations, this approach found no statistically significant bias 94 percent of the time. That is roughly what would be expected in a correctly calibrated test, since the cutoff for statistical significance is 95% confidence.
[10] This quotation is from notes taken during the meeting.
The NewsGuild of New York
1500 Broadway Suite 900
New York, NY 10036
T: 212-575-1580
info@nyguild.org